2.4. An Object Oriented Method for Database Scheme Design
In order to meet objective (iii) from section 1.4. "Objectives", a suitable data model has to be designed. The data model has to be sufficient to describe the area of application "District Health Information System". Data models are needed, to reduce the risk of inconsistent data in a database. They also help to optimize the database, while at the same time securing retrievable data. The relational data model (RM) is a widespread tool for this purpose. Since it was introduced in [CODD (1970)] it has been modified and enhanced several times. So CODD himself developed a semantic data model to "capture more meaning" in [CODD (1979)], the RM/T. The abbreviation "T" stands for the Australian province Tasmania, where the ideas for the RM/T were introduced on the "Australian Computer Science Conference" in Hobart. ([CODD (1979)], p.409). This thesis applies the modified RM/T (mRM/T) of WINTER and HAUX ([WINTER and HAUX (1994)], as cited in [MANN (1994)], p.9ff). The following sections describe a method for database scheme design with the mRM/T as introduced in [WINTER (1990b)]. The English terminology was taken from [MANN and HAUX (1993)].
Designing the database scheme is done in three steps. These steps correspond to the three levels of modelling data" in [MANN (1994)]. Differing from WINTER, the steps in this thesis were named according to these levels:
- Design of the conceptual database scheme: In this step the area of application is described with the objects in it, with their properties and with the type of their relations among each other. The whole procedure can be done using graphical elements such as boxes and arrows. Result of this procedure is the conceptual database scheme.
- Deduction of the logical database scheme: In this step the conceptual database scheme from step (1) is mapped onto elements of the relational data model. Result of this procedure is the logical database scheme.
- Realization of the physical database scheme: In this step the elements of the relational data model from step (2) are mapped onto an application software product. For this purpose the logical database scheme is translated into the physical database scheme using the means of a database management system.
2.4.1. Design of the Conceptual Database Scheme
During the design of the conceptual database scheme, four basic types of elements are identified. These are subsequently added to the conceptual database scheme. In this systematic approach, the definition of the so-called object types comes first. After the object types were taken down, characterizing relations between the object types are modelled. These are added to the conceptual database scheme. In the next stage, associating relations between the object types are identified and added to the scheme. Finally properties are assigned to each object type. The following sections describe this process and explain the needed terminology.
Object types are generated by abstracting the objects from the area of application. Basis is the systems analysis. At the end of the conceptual design the object types will receive properties. Object types and properties will result in files and fields of a file of the physical database scheme. The graphical representation of object types is done by rectangles.
Example: Let the area of application be the district health system of the fictional Kurungi District. Systems analysis in Kurungi District revealed, that there are 20 health units. Supervision is done monthly by 3 supervisors. For each supervision the supervisor fills out a report form. Each health unit provides a specific set of services and each kind of service requires a specific set of drugs. Each supervisor is also responsible for coordinating a set of services at the district level. The resulting object types are shown in the upper part of figure 2.4-1:
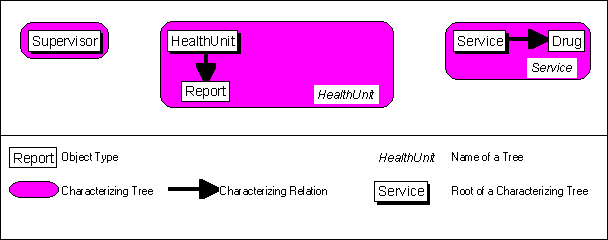
Fig. 2.4-1: In the first stage of designing the conceptual data base scheme, the scheme only contains an preliminary set of object types (upper box), which were identified from the area of application. These are supplemented with relations and properties in the next stages.

After the identification of object types, the relations between the object types are analyzed. Relations are always uni-directional. Only relations of the type (1:N) are allowed. That means, that an object of a specific object type may be related to many objects of a second object type. However, an object of the second object type may only relate to one object of the first type. Object types in a (1:1) relation are merged to one object type. When the modelling of relations is done as described in these sections, tree-like structures with one root each are created.
Characterizing relations are modelled first. These create a characterizing tree. In a characterizing relation, objects of the object type which is closer to the root are characterized by related objects of the remote object type. The objects of the remote object type can only exist, when the related object of the near object type exists. Each characterizing tree receives the name of the root. Graphically, characterizing relations are represented by black arrows from the near object type to the remote object type. A dark, rounded rectangle identifies a characterizing tree. Trees with only one object type are called trivial trees.
Example: For the fictional Kurungi District, the following characterizations can be found: A health unit is characterized by its' reports, since the reports only exist, when the health unit exists. A service is characterized by the used drugs, since the drugs are only needed, when the service is provided. The object type "Supervisor" is not involved in a characterizing relation. The resulting trees are shown in figure 2.4-2:
Fig. 2.4-2: Characterizing relations were added to the conceptual database scheme. The characterizing trees were identified and depicted.
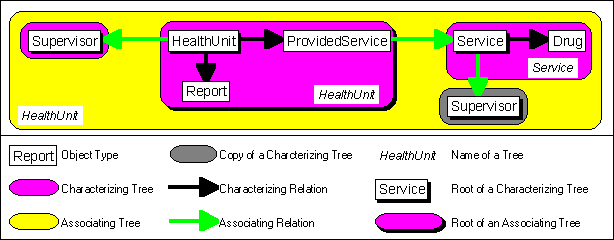
After identifying characterizing relations, the associating relations have to be inspected. Associating relations create an associating tree. In an associating relation, an object from the object type which is closer to the root associates an object of the remote object type. An object of the remote object type can still exist, when no related object of the near object type exists. Object types in an associating relation may not be within the same characterizing tree. Also, each characterizing tree may be associated only once. If it is necessary to associate an object type from a characterizing tree which was associated already, a copy of the associated tree must be created. In the physical database scheme it is sufficient to realize the copies with different views on the associated tree.
In the graph, associating relations are represented by grey arrows from the near object type to the remote object type. An associating tree is identified by a light rounded rectangle. If the database scheme decomposes into separate associating trees, these should be treated as different database schemes. Each associating tree receives the name of the root. Associating trees with only one characterizing tree are called trivial associating trees.
Example: In the fictional area of application "Kurungi District", the following associating relations can be found: A health unit is supervised by one supervisor. It associates the supervisor, since the supervisor is independent of the existence of the health unit. A health unit provides several services. Since a service can also be provided by several health units, this is not an (1:N) relation. Therefore the new object type "ProvidedService" has to be introduced in a characterizing relation to the object type "HealthUnit" and an associating relation to the object type "Service". Additionally, a service is coordinated by a supervisor. Since the trivial characterizing tree "Supervisor" was associated already by "HealthUnit", a copy of "Supervisor" has to be associated. This represents another function of "Supervisor". Figure 2.4-3 shows the conceptual database scheme after the associating relations and the associating tree were identified:
Fig. 2.4-3: Associating relations were added to the conceptual database scheme. The associating trees were identified and depicted.
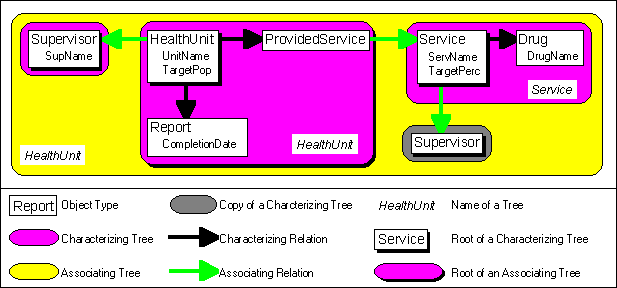
Finally properties are assigned to the object types. Properties of an object type are descriptions of that object type, which are functional independent. That means that a property can not be generated from other properties. If a property can be generated from other properties, it has to be mapped as a characterizing or associating relation. In the graph, the properties are added to the object type.
Example: For the object types of the fictional area of application "Kurungi District", the following properties are assigned: The object type "Supervisor" has the property "SupName", the object type "HealthUnit" has the properties "UnitName" and "TargetPop", which represents total target populations of health units. The object type "Report" receives the property "CompletionDate". "CompletingSupervisor" is not a valid property for the object type "Report", since the name of the supervisor can be retrieved using the relations from the object type "HealthUnit" to the object types "Supervisor" and "Report". The object type "Service" has the properties "TargetPerc", which represents percentages of total target populations, and "ServName". The object type "Drug" receives the property "DrugName". "Target Population of Provided Service" is not allowed as property for the object type "ProvidedService", since it can be calculated from the properties "TargetPerc" of the object type "Service" and "TargetPop" of the object type "HealthUnit". These can be retrieved via the relations from the object type "HealthUnit" to the object type "ProvidedService" and from the object type "ProvidedService" to the object type "Service". Figure 2.4-4 shows the conceptual database scheme after insertion of properties:
Fig. 2.4-4: The conceptual database scheme is complete after insertion of the relevant properties.
2.4.2. Deduction of the Logical Database Scheme
After the design of the conceptional database scheme, the logical database scheme can be deducted. In this stage the elements "object", "object type", "relation" and "property" are mapped on elements of the relational data model (compare [CODD (1970)]). Object types turn to relation variables and properties are transformed into attributes of the relation variables. Objects are described by tupels of values of the attributes.
The additional introduction of surrogate keys enables the mapping of relations. A surrogate key is a special attribute, which is added to a relation variable to identify specific tupels. It may contain unique numbers, which are invariant over time. Their only meaning must be the identification of a tupel of values. For the mapping of characterizing relations, the surrogate key from the relation variable of the characterized object type is added to the relation variable of the characterizing object type. Associating relations are mapped by adding the surrogate key from the relation variable of the associating object type to the relation variable of the associated object type. The surrogate keys which were added because of the characterizing and associating relations will contain the references to the surrogate keys of the involved tupels.
Example: The conceptual database scheme of the fictional area of application "Kurungi District" can be deducted into a set of relation variables The resulting relation variables are listed in table 2.4-1. The names of the surrogate keys consist of the name of the relation variable plus the "#" symbol:
Tab. 2.4-1: Relation variables and attributes which were deducted from the conceptual database scheme.
| Relation Variable | Attributes of the Relation Variable |
| SUPERVISOR | {Supervisor#, SupName} |
| HEALTHUNIT | {HealthUnit#, Supervisor#, UnitName, TargetPop} |
| SERVICE | {Service#, Supervisor#, ServName, TargetPerc} |
| REPORT | {Report#, HealthUnit#, CompletionDate} |
| PROVIDEDSERVICE | {ProvidedService#, HealthUnit#, Service#} |
| DRUG | {Drug#, Service#, DrugName} |
Assuming that the health units of the fictional "Kurungi District" are supervised by Mr. Romeo Araali and Mrs. Julia Abooki, the relation variable SUPERVISOR will contain the tupels from table 2.4-2:
Tab. 2.4-2: Tupels of the relation variable SUPERVISOR.
| Supervisor# | SupName |
| 5 | Romeo Araali |
| 8 | Julia Abooki |
Mr. Araali is responsible for supervising the health units "Ekuminebili" and "Muende", while Mrs. Abooki supervises "Mukage" and "Asatuneina". Resulting from this, the relation variable HEALTHUNIT will contain the tupels from table 2.4-3:
Tab. 2.4-3: Tupels of the relation variable HEALTHUNIT.
| HealthUnit# | Supervisor# | UnitName | TargetPop |
| 6 | 8 | Mukage | 25700 |
| 9 | 5 | Muende | 32500 |
| 12 | 5 | Ekuminebili | 27300 |
| 34 | 8 | Asatuneina | 31800 |
From tables 2.4-2 and 2.4-3 it can be seen, that when the tupel of a health unit is known, it is possible to retrieve the information about the according supervisor by using the surrogate key Supervisor#. On the other hand, when the tupel of a supervisor is known, it is also possible to generate a list of the health units, which are supervised by this supervisor.
WINTER also describes a formal representation of the logical database scheme in [WINTER (1990a)]. In that context he introduces functions, which allow the use of semantic integrity constraints to control characterizing and associating relations. These can be applied, when the formal description of the logical database scheme is needed. For this thesis the informal description of the database scheme as done in the above example shall be sufficient, though.
2.4.3. Realization of the Physical Database Scheme
The last step of database scheme design codes the elements of the logical database scheme into structures and commands of the chosen database management system. Therefore this step depends very much on the type of database management system. There are many different systems by now, which support the relational data model to varying extents. Some database management systems allow a mere definition of the needed relation variables and semantic integrity constraints. The supervision of data integrity is done by the data base management system automatically. In other database management systems there is almost no automatic integrity control. Integrity control has to be provided by the programmer. Table 2.4-4 lists the elements of the conceptual and logical database scheme and their equivalents in a database management system at the example of the "Clipper" programming language:
Tab. 2.4-4: Corresponding elements during the different stages of database scheme design.
| Conceptual Database Scheme | Logical Database Scheme | Physical Database Scheme |
| object types | relation variables | database files |
| properties | attributes | fields |
| descriptions of an object | expressions | values |
| objects | tupels of expressions | records of values |
| relations | deducted into: | realized through: |
| - surrogate keys | - not available, must be coded using numeric fields and a database file for incrementing unique integers. |
| - semantic integrity constraints | - not available, must be coded using the "Clipper" commands. |
When coding the data base scheme, the constraints of the chosen database management system must be taken into account. Modifications of the database scheme might be necessary for a better performance of the resulting software application product.